 LinMao's Blog(林茂的博客)
LinMao's Blog(林茂的博客)执行模型
CUDA程序执行流程一般如图:
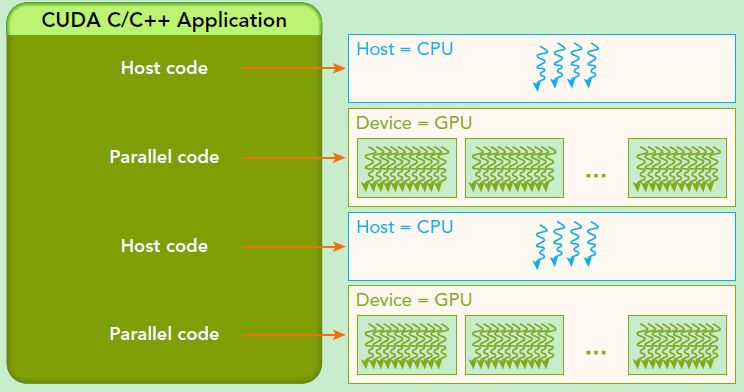
GPU架构是围绕一个流式多处理器(SM)的可扩展阵列搭建的。从软件上看,SM更像一个独立的CPU core。SM(Streaming Multiprocessors)是GPU架构中非常重要的部分,GPU硬件的并行性就是由SM决定的。以Fermi架构为例,其包含以下主要组成部分:CUDA核心,共享缓存/L1 Cache,寄存器文件,加载/存储单元,特殊功能单元(SFU),线程束调度器。
CUDA采用单指令多线程(single-instruction-multiple-threads, SIMT)架构来管理和执行线程,每32个线程为一组,被称为线程束(warp)。线程束中的所有线程同时执行相同的指令。每个线程都有自己的指令地址计数器和寄存器状态,利用自身的数据执行当前的指令。每个SM都将分配给它的线程块划分到包含32个线程的线程束中,然后在可用的硬件资源上调度执行。warp内遵循lockstep规则,即所有线程同步执行。在SM里,warp是基本的调度、执行和读写cache/memory的单元。
一个线程块(block)只能在一个SM上被调度。一旦线程块在一个SM上被调度,就会保存在该SM上直到执行完成。在同一时间,一个SM可以容纳多个线程块。
当线程束(warp)由于任何理由闲置的时候(如等待从设备内存中读取数值),SM可以从同一SM上的常驻线程块中调度其他可用的线程束。在并发的线程束间切换并没有开销,因为硬件资源已经被分配到了SM上的所有线程和块中,所以最新被调度的线程束的状态已经存储在SM上。
线程分化
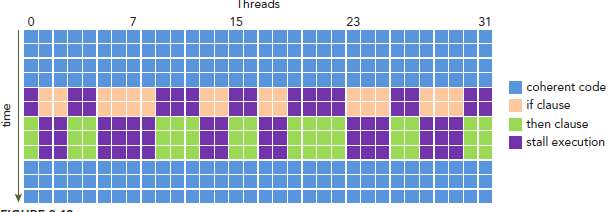
如果一个warp里的线程在某个点(if-else等)出现了分化(warp divergence),则所有的分支顺序执行。执行if的时候,else的线程被挂起。在分化(if-else)结束以后,再继续lockstep的执行。warp divergence造成了巨大的overhead。warp divergence如下图。
栅栏同步
CUDA中,同步可以在两个级别执行:
- 系统级:等待主机和设备完成所有的工作
- 块级:在设备执行过程中等待一个线程块中所有线程到达同一点
许多CUDA API的调用和CUDA内核函数的启动是异步的。cudaDeviceSynchronize函数可以用来阻塞主机应用程序,直到所有的CUDA操作(复制、核函数等)完成。
|
1 2 3 |
cudaError_t cudaDeviceSynchronize(void); # 这个函数可能会从先前的异步CUDA操作返回错误 |
因为在一个线程块中线程束以一个未定义的顺序被执行,CUDA提供了一个使用块局部栅栏来同步它们的执行的功能。使用下述函数在内核中标记同步点:
|
1 2 |
__device__ void __syncthreads(void); |
当__syncthreads被调用时,在同一个线程块中每个线程都必须等待直至该线程块中所有其他线程都已经达到这个同步点。在栅栏之前所有线程产生的所有全局内存和共享内存访问,将会在栅栏后对线程块中所有其他的线程可见。该函数可以协调同一个块中线程之间的通信,但它强制线程束空闲,从而可能对性能产生负面影响。
Reference:


最新评论
感谢博主,让我PyTorch入了门!
博主你好,今晚我们下馆子不?
博主,你的博客用的哪家的服务器。
您好,请问您对QNN-MO-PYNQ这个项目有研究吗?想请问如何去训练自己的数据集从而实现新的目标检测呢?
where is the source code ? bomb1 188 2 8 0 0 hello world 0 0 0 0 0 0 1 1 9?5
在安装qemu的过程中,一定在make install 前加入 sudo赋予权限。
所以作者你是训练的tiny-yolov3还是yolov3...
很有用