 LinMao's Blog(林茂的博客)
LinMao's Blog(林茂的博客)
创建数据集
PyTorch 有两种方式来处理数据,一种 torch.utils.data.Dataset 和 torch.utils.data.DataLoader,前者存储数据集和对应的label,后者封装数一个数据集的可迭代对象。
|
1 2 3 4 5 |
import torch from torch.utils.data import DataLoader from torchvision import datasets from torchvision.transforms import ToTensor |
PyTorch 提供一些不同领域特有的库,比如 torchtext,torchvision,和 torchaudio。这些库包含对应的领域的常见数据集,模型,和操作。torchvision.datasets 包含许多计算机视觉方向的数据集,比如,CIFAR,COCO,等等(包含的所有数据集)。每一个 torchvision dataset 包含两个选项:transform 和 target_transform 来修改数据和label。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 本教程以 FashionMNIST 数据集为例子,这个数据集包含了 10 个类别,共计 7 万张灰度图像。 # 我们使用其中 60,000 张图像训练网络,使用另外 10,000 张图像评估训练得到的网络 # PyTorch 提供了专门的模块加载 FashionMNIST 数据集,见 torchvision.datasets。 training_data = datasets.FashionMNIST( root="data", train=True, download=True, transform=ToTensor(), ) test_data = datasets.FashionMNIST( root="data", train=False, download=True, transform=ToTensor(), ) |
接下来,将 dataset 作为参数传到 DataLoader。DataLoader 提供一个可迭代对象,能够自动的 batching,sampling,shuffling,和 multiprocess data loading。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 使用 DataLoader 来帮助我们把数据分成 batch_size=64 的小块,此外还可以打乱数据。 batch_size = 64 # 创建训练数据集的数据加载器 train_dataloader = DataLoader(training_data, batch_size=batch_size) test_dataloader = DataLoader(test_data, batch_size=batch_size) print(type(test_dataloader)) for X, y in test_dataloader: # dataloader 里面的数据是以 batch_size 为单位的<tensor, tensor>,其中第一个 tensor 是图像,第二个 tensor 是标签。 print(type(X), type(y)) print("Shape of X [N, C, H, W]: ", X.shape) print("Shape of y: ", y.shape, y.dtype) break |
|
1 2 3 4 5 |
<class 'torch.utils.data.dataloader.DataLoader'> <class 'torch.Tensor'> <class 'torch.Tensor'> Shape of X [N, C, H, W]: torch.Size([64, 1, 28, 28]) Shape of y: torch.Size([64]) torch.int64 |
显示数据集
为了比较直观看看数据集的样子,下面代码显示数据集图标和标签,这一步在训练的时候是不需要的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import matplotlib.pyplot as plt %matplotlib inline import numpy as np import torchvision def imshow(img): img = img / 2 + 0.5 # unnormalize,因为 ToTensor() 把数据归一化了 npimg = img.numpy() # 把 tensor 转换成 numpy 数组 plt.imshow(np.transpose(npimg, (1, 2, 0))) # 把通道维度放到最后,因为 matplotlib 需要的是 (H, W, C) plt.show() # 显示图片 dataiter = iter(train_dataloader) # 创建一个迭代器 images, labels = next(dataiter) # 返回一个 batch 的数据 imshow(torchvision.utils.make_grid(images)) # 把这个 batch 的图像拼成一个网格 print(' '.join('%5s' % training_data.classes[labels[j]] for j in range(batch_size))) # 打印这个 batch 的标签 |
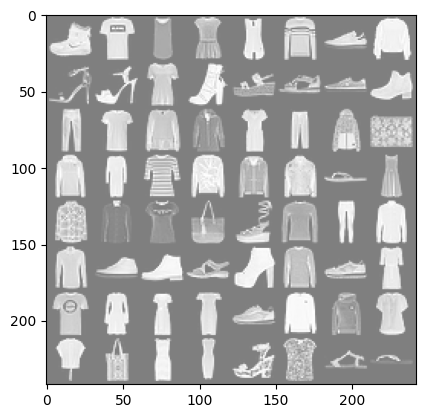
|
1 2 |
Ankle boot T-shirt/top T-shirt/top Dress T-shirt/top Pullover Sneaker Pullover Sandal Sandal T-shirt/top Ankle boot Sandal Sandal Sneaker Ankle boot Trouser T-shirt/top Shirt Coat Dress Trouser Coat Bag Coat Dress T-shirt/top Pullover Coat Coat Sandal Dress Shirt Shirt T-shirt/top Bag Sandal Pullover Trouser Shirt Shirt Sneaker Ankle boot Sandal Ankle boot Pullover Sneaker Dress T-shirt/top Dress Dress Dress Sneaker Pullover Pullover Shirt Shirt Bag Dress Dress Sandal T-shirt/top Sandal Sandal |
创建模型
在 PyTorch 中,通过继承类 torch.nn.Module 来定义一个网络模型,神经网络的层定义在 __init__ 函数中,并通过 forward 函数来指定数据是如何在网络中传递的。如果平台允许,可以将网络移动到 GPU 来加速神经网络的计算。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 构建神经网络 import torch.nn as nn device = "cuda" if torch.cuda.is_available() else "cpu" print("Using {} device".format(device)) # 定义网络 class NeuralNetwork(nn.Module): def __init__(self): super(NeuralNetwork, self).__init__() # flatten 层把尺寸为 (n, m, x, y) 的输入转换成 (n, m * x * y) 的输出, n 是 batch_size self.flatten = nn.Flatten() # Sequential 是一个有序的容器,神经网络层将按照在传入构造器层对象的顺序依次被添加到计算图中执行 self.linear_relu_stack = nn.Sequential( nn.Linear(28*28, 512), # 输入层,Linear 是全连接层 nn.ReLU(), # 激活函数 nn.Linear(512, 512), # 隐藏层 nn.ReLU(), # 激活函数 nn.Linear(512, 10) # 输出层 ) def forward(self, x): # x = self.flatten(x) # x = self.linear_relu_stack(x) # return x return self.linear_relu_stack(self.flatten(x)) model = NeuralNetwork().to(device) # 实例化网络,把它移动到 GPU 上(如果有的话) print(model) |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Using cuda device NeuralNetwork( (flatten): Flatten(start_dim=1, end_dim=-1) (linear_relu_stack): Sequential( (0): Linear(in_features=784, out_features=512, bias=True) (1): ReLU() (2): Linear(in_features=512, out_features=512, bias=True) (3): ReLU() (4): Linear(in_features=512, out_features=10, bias=True) ) ) |
模型参数优化(训练)
为了训练神经网络,需要定一个损失函数(loss function)和优化器(optimizer)。 损失函数:用来评估模型的预测值 f(x) 与真实值 Y 的不一致程度,是一个非负的实值函数,通常用 L(Y, f(x)) 来表示,损失函数越小,模型越好。
优化器:在深度学习反向传播过程中,指引损失函数(目标函数)的各个参数往正确的方向更新合适的大小,使得更新后的各个参数让损失函数值不断逼近全局最小。
|
1 2 3 |
loss_fn = nn.CrossEntropyLoss() # 损失函数, 交叉熵损失函数, 用于分类问题, 用于计算模型输出与真实标签之间的误差 optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) # 优化器, 随机梯度下降, 学习率为 0.001, 用于优化模型参数, 使损失函数最小化 |
在一次模型训练迭代中,模型以 batch 为单位的训练集上进行预测,然后反向传播预测的错误来调整模型的参数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
def train(dataloader, model, loss_fn, optimizer): size = len(dataloader.dataset) # 训练集的大小 model.train() # 设置模型为训练模式 for batch, (X, y) in enumerate(dataloader): # 遍历数据集, batch 为索引, (X, y) 为数据, enumerate() # 每次取出一个 batch 的数据, X 为图像, y 为标签 X, y = X.to(device), y.to(device) # 前向传播 pred = model(X) loss = loss_fn(pred, y) # 反向传播 loss.backward() # 执行链式求导计算梯度, 梯度存储在每个参数的 .grad 属性中, optimizer.step() # 优化器根据梯度更新参数, optimizer.step() 会更新所有参数, 使损失函数最小化 optimizer.zero_grad() # 每次反向传播之前需要清零梯度, 否则梯度会累加 if batch % 200 == 0: loss, current = loss.item(), batch * len(X) # loss.item() 获取损失函数的值, batch * len(X) 为已经训练的样本数量 print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]") def test(dataloader, model, loss_fn): size = len(dataloader.dataset) # 测试集的大小s num_batches = len(dataloader) # batch 的数量, 用于计算平均损失, 也就是每个样本的平均损失, 用于评估模型 model.eval() # 设置模型为评估模式 test_loss, correct = 0, 0 with torch.no_grad(): # 不计算梯度 for X, y in dataloader: X, y = X.to(device), y.to(device) pred = model(X) test_loss += loss_fn(pred, y).item() # 累加损失, 用于计算平均损失 correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 累加正确预测的数量, 用于计算准确率 # pred.argmax(1) 返回每个样本预测的标签, .type(torch.float) 把布尔值转换成浮点数, .sum() 计算预测正确的数量 test_loss /= num_batches correct /= size print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n") |
训练过程通常会进行多个iterations(epochs)。在每个epochs,模型学习新的参数来达到更好的预测效果。上面代码中打印每一个 epochs 里面准确率和误差,随着 epochs 的增加,通常希望看到准确率增加,误差减少。
|
1 2 3 4 5 6 7 |
epochs = 2 for t in range(epochs): print(f"Epoch {t+1}\n-------------------------------") train(train_dataloader, model, loss_fn, optimizer) test(test_dataloader, model, loss_fn) print("Done!") |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
Epoch 1 ------------------------------- loss: 2.293925 [ 0/60000] loss: 2.277599 [12800/60000] loss: 2.253120 [25600/60000] loss: 2.233092 [38400/60000] loss: 2.193248 [51200/60000] Test Error: Accuracy: 43.5%, Avg loss: 2.162803 Epoch 2 ------------------------------- loss: 2.163640 [ 0/60000] loss: 2.107546 [12800/60000] loss: 2.081974 [25600/60000] loss: 2.045840 [38400/60000] loss: 1.968041 [51200/60000] Test Error: Accuracy: 56.1%, Avg loss: 1.897162 Done! |
模型保存与加载
保存模型
当模型训练完了,需要将模型保存到文件,便于下次接着训练,或者在部署时使用。保存模型通常就是序列化地保存内部状态字典(internal state dictionary),内部状态字典包含模型的权重。
|
1 2 3 |
torch.save(model.state_dict(), "model.pth") print("Saved PyTorch Model State to model.pth") |
|
1 2 |
Saved PyTorch Model State to model.pth |
加载模型
加载模型包含重新创建模型结构和加载状态字典(权重)。
|
1 2 3 |
model = NeuralNetwork().to(device) model.load_state_dict(torch.load("model.pth")) |
|
1 2 |
<All keys matched successfully> |
使用模型
将上面加载的模型来做预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
classes = [ "T-shirt/top", "Trouser", "Pullover", "Dress", "Coat", "Sandal", "Shirt", "Sneaker", "Bag", "Ankle Boot", ] model.eval() x, y = test_data[0][0], test_data[0][1] # 显示这个图像 imshow(torchvision.utils.make_grid(x)) print(''.join('%5s' % classes[y])) with torch.no_grad(): x = x.to(device) pred = model(x) predicted, actual = classes[pred[0].argmax(0)], classes[y] print(f'Predicted: "{predicted}", Actual: "{actual}"') |
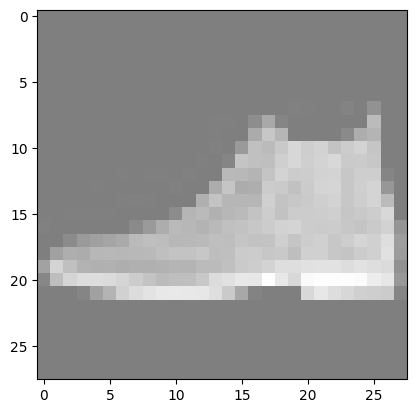
|
1 2 3 |
Ankle Boot Predicted: "Ankle Boot", Actual: "Ankle Boot" |
总结
之前只有过用 Darknet 训练目标识别神经网络的经历,对于 PyTorch 训练神经网络的过程其实一直不是很熟悉。用 Darknet 训练的过程:首先是制作数据集,制作数据集的时候要手动的把照片和标签放到指定的文件夹,然后写清楚类别和数据集信息;然后是训练,选择合适网络配置文件(cfg 文件),设置里面的各种超参数,和指定生成的权重文件;最后是测试,读取训练的权重然后测试输入的图片。其实 PyTorch 和这个过程本质上是一样的:PyTorch 首先也是创建数据集,与 Darknet 需要手动创建不同,PyTorch 可以通过代码来提供数据集,并且常见的数据集都包含在 torchvision,torchtext,和torchaudio里面,这就给开发者极大的方便,另外,这三个库不仅包含相应领域常见的数据集,还包括了相应领域的常见操作的库。另外,数据集通过 DataLoader 封装成可迭代的对象,极大的方便了使用数据集,并且不同数据集的使用方式是统一的。与Darknet 里面通过 cfg 文件来定义模型不一样,PyTorch 里面通过继承 torch.nn.Module 类来定义模型,模型结构定义在类中的 __init__ 函数中,这一点也比较灵活。接着就是 PyTorch 的训练,感觉训练与 Darknet 的区别很大,PyTorch 模型结构定义与损失函数和优化器定义是分开的。感觉 Darknet 里面好像并没有着重讨论这个部分,我猜测可能是把这部分和模型绑定直接写到了 cfg 文件了,也有可能是当时的模型比较简单,使用的损失函数和优化器种类有限,所以没有提供自定义的选项。PyTorch 里面提供这些,可以让模型研究者灵活调用,很容易设计出他们自己的模型,可能这就是 PyTorch 能够如此成功的原因吧。另外还有一个,PyTorch 提供链式求导和使用优化器更新参数,就需要调用 loss.backward() 和 optimizer.step() 两个 API 就把反向传播,梯度下降,权重更新给完成了,不可谓不神奇,这一部分如果要是自己实现,是又麻烦又容易出错。另外,在训练的时候,数据集在创建 DataLoader 的时候根据 batch size 生成对应的迭代对象,然后在训练时只需要遍历迭代对象就可以,每次取出的 batch size 个 数据标签对,放到模型中计算。整体感觉 PyTorch 让定义一个模型的过程变得更加快捷简单,并且内置了丰富的数据集,让对模型的验证也变得非常简单,经过这个过程,确实更加深刻的理解了 PyTorch 的优势了。
另外,对于几个概念也有了一个认识,PyTorch 里面的 batch size 是作用于 DataLoader,从而让一次训练迭代输入更大的数据。所有数据完整训练一遍称之为一个 epoch。另外,对于模型而言,有一个概念之前一直没有搞明白,就是 iteraion。我不知道深度学习里面是不是真的有这个概念,但是我之前 project 讨论的时候经常提到这个概念:就是对于给定输入,神经网络走完一遍网络计算图(正向或者反向)的过程。有一个疑问是,这个过程中,对于给定的 batch size,是 batch size 张图片同时输入并参与一次正向传播,还是这些图片一张一张参与正向。这是一个非常存疑的问题,我倾向于前者,但是后者似乎也能说得通。mark一下,后续解决。


感谢博主,让我PyTorch入了门!
哈哈哈,咋还回复上了,现在才看到…
对于iteration,从网络的训练的角度就是step,但是也叫iteration(https://pytorch.org/tutorials/intermediate/tensorboard_profiler_tutorial.html#use-profiler-to-record-execution-events)